The purpose of a ROOT dictionary
Why is are ROOT dictionaries needed?
Maybe they’re not. Let’s take a look at the sketch I showed during the class introduction: 1
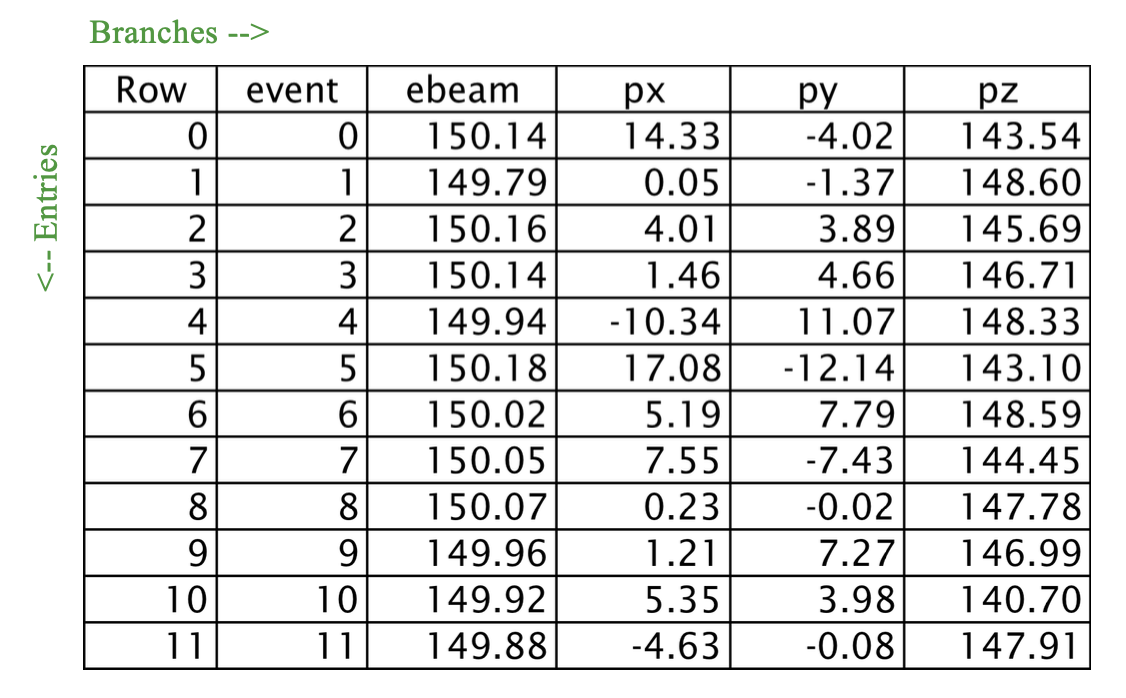
Figure 129: A portion of our old friend, experiment.root. Is this a table,
a spreadsheet, a dataframe, an n-tuple, or a ROOT TTree? The answer:
yes!
Let’s consider the columns of that n-tuple more formally, as Branches
of a TTree. To create
a new TTree, and add a branch like ebeam to that TTree, the typical
syntax is:
// The variable we'll write to a branch.
float ebeam;
// Open a new ROOT file.
TFile file("tree.root","recreate");
// Create a tree within that file.
TTree* tree = new TTree("myTree","example tree creation");
// Create a branch within that tree, whose values are defined by the
// variable ebeam.
tree->Branch("myBranch",&ebeam);
// Create a large number of entries (rows) within this tree.
const int numberEvents = 100000;
// For each entry...
for (event=0; event<numberEvents; event++) {
// Create a random value for ebeam.
ebeam = gRandom->Gaus(150.,.15);
// Add a new entry to the tree. Because of the 'tree->Branch'
// method above, ROOT automatically knows to store the contents of
// variable ebeam to the branch 'myBranch'.
tree->Fill();
}
// Make sure the tree is written to the output file.
tree->Write();
If you’d like to see a more complete example, see my file
CreateTree.C;
that’s the program I used to create experiment.root back in
2001.
What’s not obvious from Listing 58 is that ROOT needs to know how to write (or read) the type of variable in a branch. “Under the hood”, ROOT needs to have an underlying mechanism to include the variable in the output file.2
In that example, note that ebeam is a fundamental C++ type:
float. If a branch in a tree is one of those fundamental types (int, float,
double, etc.; there’s a complete list on the
TTree web page) you
don’t need a dictionary.3
Going back to Figure 129, what if you want to have a more complex structure in one of those branches of the tree?
Why would you want this?
If you’re not familiar with physics data analysis, it’s natural to ask why would anyone want to do this? Isn’t a spreadsheet good enough?
In physics4 it’s more common than not to require a variable number of values to describe some process; in other words, there’s no longer a fixed value of “n” in the term “n-tuple”.
Here’s a simple example: On the page that
introduces the n-tuple in the file experiment.root, I describe
an absurdly simple event in which an entry describes a single particle
scattering only once in a detector. In a more realistic example, a
particle could scatter multiple times in a single event, and each
individual particle would scatter a different number of times. If a
particle scatters N times, you might want to have the values
(zv,px,py,pz) for each one of the scatters.
Figure 130: A sketch of multiple scatters for a single particle.
One way of structuring that data is to have a
vector for each
one of those values. That is, zv would no longer be represented by a
single value, but by a vector \((\textrm{zv}_{1}, \textrm{zv}_{2},
\ldots \textrm{zv}_{N})\). By definition, each vector in an entry will
have a length of N, but the value of N will be different for each
entry.
Even that’s too simple. What if multiple particles are going through
the detector at once? You’ll need a “zv-vector” for each one of
those particles; perhaps by a vector of particles each containing its
own vector of scatters; a “vector of vectors”. (The ATLAS
experiment has roughly a billion interactions
per second, with each interaction creating thousands of particle
tracks.)

Figure 131: A sketch of multiple scatters for multiple particles.
As I noted in Exercise 15: Data reduction (working with TTrees), the focus of the basic tutorial was analyzing an n-tuple of the kind that might come at the end of a much longer data analysis. But take one step up in an analysis chain, and the structure of your tree branches (assuming that the experiment even uses ROOT-format files) becomes much more complex.
Now you may finally understand why the “tree” metaphor permeates the ROOT package.
If the branch is going to have a type of vector<T> where T is one
of the basic
The code for putting vectors into a tree branch is almost the same as the code in Listing 58; for example:
std::vector<float> energies;
tree->Branch("energyBranch",&energies);
Consider more complex structures, such as:
an STL map
a “vector of vectors” such as
std::vector<std::vector<double>>
For any of the above, you need to have code to teach ROOT how to write and read that data. That’s what a ROOT dictionary does.6
Fortunately, the process for creating a ROOT dictionary is fairly well automated. We’ll go over the procedure in the next two sections.
- 1
This assumes you took the tutorial at Nevis.
- 2
In general, the process for converting an object into a format that can be read from or written to a file is called serialization.
- 3
If your first introduction to C++ pointers was my pointers page, then the
&operator in Listing 58 (&ebeam) may be completely opaque to you. The&means to dereference a variable.Here’s my overly-simplified explanation: Supposed you have a variable
myVar, and you want the address (memory location) of that variable. Then&myVaris the address ofmyVar.If you ask “Why do you need this?” remember that C++ is a strongly-typed language. When you define a method or function, you have to specify the types of all its arguments. Case in point: the
TTree::Branch()method needs the variable that contains the value that will be copied to the branch.Instead of ROOT having to know the type of every variable that might conceivably be written to a tree (which is impossible; that’s why dictionaries are necessary), ROOT’s procedure is to have us take the address of the variable and pass that as an argument. No matter what the type of the variable
myVar(int,float,double, etc.) the formal type of&myVaris always the special C++ pointer type,void*.Confused? For now, just note the pattern in the example code. If you get into
C++ memory management, this concept will become clear.- 4
Other sciences and analyses require more complex structures than simple dataframes or spreadsheets. But since I am a physicist, not an accountant or a phlebotomist, I’ll only speak for the analysis methods I know.
- 5
If you looked at that web page, you’ll see that ROOT can handle other STL containers directly:
std::list,std::deque,std::set,std::multiset. These other container types have properties that are useful in a broader data-management context, but within the domain of physics they don’t have much utility.What they all have in common is that they’re “linear”: they contain a sequence of values. For example, a deque is like a vector, except that you can quickly insert a value to either the beginning or end of a deque (you can only quickly insert a value to the end of a vector; if you insert a value to the beginning of a vector, the entire sequence has to be moved in computer memory to make room for the new value).
If you think about it for a second, you’ll realize that the ROOT I/O for any pre-defined linear container is basically the same: iterate over all the values in sequence and read/write those values. That’s why ROOT supports all those containers; some ROOT coder realized the similarity and quickly adapted the vector code into the other linear types.
- 6
If you’re a Python programmer, you may be familiar with pickle, a package for serializing Python objects. Python’s pickle is pretty much limited to just Python, while (as we’ll see) ROOT’s dictionaries can be used within either C++ or Python.