Friends: n-tuple columns in multiple files
The previous section talked about Chains, in which an n-tuple’s rows were distributed across multiple files. With ROOT’s Friends, we have a way of distributing an n-tuple’s columns across multiple files.
Why?
At this point, it’s reasonable to ask: Why would you want do this?
The full answer is long. For the moment, I want to focus on the “how”: How to read an n-tuple whose columns have been divided across multiple files. I’ll get to the “why” further down the page.
Using ROOT Friends is about as simple as using chains. The main difference is that, with Friends, typically the
n-tuples in each of the Friends’ files have different names, so you
have to include the n-tuple name in AddFriend.

Figure 71: A diagram of a simple case of using AddFriend.
The above diagram shows an extremely simple example of joining columns between
files. We see the columns (Branches) from our friend1 experiment.root
split between three n-tuples in three files:
the n-tuple
expTreein filefile1.rootthe n-tuple
zvTreein filezv.rootthe n-tuple
chi2Treein filechi2.root
Because this is a slide from a C++ talk, the example code in Figure 71 uses TTreeReader to access the columns of the Friends. However, the same procedure applies no matter which language you use to access the tree:
Open one of the files.
Use
AddFriend(<ntuple-name>, <file-name>)on each of the remaining files.
After that, you can access the columns of the extended n-tuple as if they were all part of the initial tree.
Here’s Python code that corresponds to the C++ code in Figure 71.
import ROOT
expFile = ROOT.TFile( 'file1.root' )
expTree = ROOT.gDirectory.Get( 'expTree' )
expTree.AddFriend("zvTree", "zv.root")
expTree.AddFriend("chi2Tree", "chi2.root")
entries = expTree.GetEntriesFast()
for jentry in range ( entries ):
# Work with expTree.ebeam, expTree.zv, expTree.chi2, and so on...
Why? Because…
Now I’ll answer the question I posed above: Why would you want to do this?
The work you may have done in college courses, and the Exercises in this tutorial, involve running a single program. Typically the program reads in one file as input and perhaps write one file as output.
However, for a large-scale data analysis project that might have many steps (and many programmers developing each step), that’s not how it works. Here’s a simple example:
Program A reads
file1.root, does some computations, and produces an n-tuple infile2.root.Program B reads
file2.root, performs more computations, and creates an n-tuple infile3.root.Program C reads
file3.root, and produces another n-tuple infile4.root.and so on.
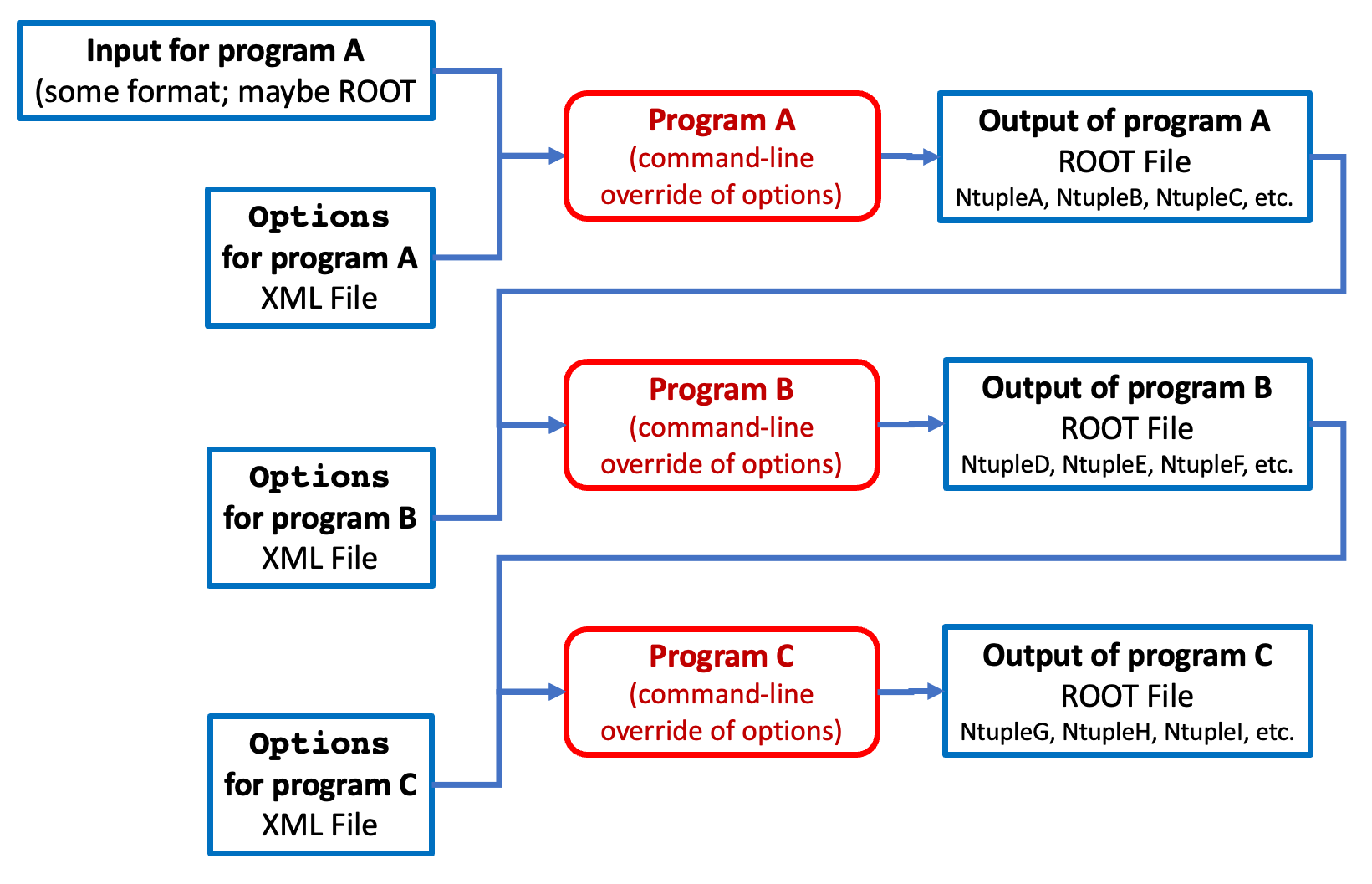
Figure 72: Here’s a diagram of a hypothetical physics analysis chain from a project I wrote. The original purpose of the diagram was to illustrate how program options can be used to control the processing of the individual tasks. Here, I ask that you focus on how the output of program A becomes the input of program B, and so on.
A “why?” within a “why?”
If your prior experience in program development has been working within a Jupyter notebook, the above breakdown of a task into several programs may seem unnecessary. Why not just write one big program? It might take a long time, but so what?
The answer is that programs A, B, C, etc., can do very different things. The differences are great enough that expertise begins to develop within those tasks: Alice is an expert on what Program A does; Bob is an expert on Program B; Chris has spent their life learning about C;2 etc.
If I’m the one supervising Alice, Bob, Chris, Diane, and the rest of the programming team, I don’t want them wasting their time coordinating their efforts to edit a single big program file. I want Alice to focus on A, Bob on B, etc.
There’s another issue that frequently comes up in physics analyses: Perhaps program A takes a long time to run, and is rarely changed. Program B takes only a short time to run, but the physics model implemented by program B is undergoing constant revision.
If everything were “mushed” into one program, you’d have to re-run the whole thing every time you changed the “model B” physics. With different physics separated into different programs, you’d only have to re-run program B as your understanding of B physics improves.3
It’s the need for multiple programs and data passes that makes Friends–
Wait a second
Do we really need to use ROOT Friends for this? You’re reading more input files with each program further down the analysis chain. What if we had Program B write a longer n-tuple containing all of A’s output, then Program C writes a file containing A’s and B’s output, and so on. At each step there’d be only one file to read.
Ah, now you’re thinking! Excellent!
However, it’s still more efficient to use Friends:
As you worked through the Exercises in the tutorial, especially on The RDataframe Path, you may have noticed that when you open an n-tuple file, you don’t have to know about every single column in an n-tuple in order to read it; you can focus on just the columns you need.
With your approach, every program in the analysis chain would have to “know” about every column in all the upstream programs. For example, program C would have to read in all the columns created by program A in order to copy them to its output for program D.
With Friends, program A could write its columns, but if only program D needs them, programs B and C could ignore them.
Consider: What if Diane, the physicist working on program D, realizes that they need an additional field from program A? With Friends, only programs A and D would have to be revised. If we rely on each program reading and writing all the columns created upstream, every program in the chain would have to be revised.
If you skip ahead to the advanced data reduction exercise or the appendix on creating a ROOT dictionary, you’ll see that writing n-tuple columns (or
TTreebranches) can get tedious.If you have to copy an ever-increasing number of columns as you go down the programs in the analysis chain, by the time you get to program E, most of its code might consist of copying n-tuple columns.
As you add more columns to the files in the analysis chain, the files grow bigger, and you get more of them. This is particularly an issue when you’re submitting large-scale batch jobs that involve running the analysis chain thousands of times. You’ll have a large number of outputs of program A, of program B, and so on.
If each file duplicates information from programs earlier in the analysis chain, you could be wasting a considerable amount of disk space.
That’s easy to fix! Just delete the old files when you’re through with them.
That doesn’t happen. You always want to keep your old files, just in case you need to trace a problem.
Physicists only like to delete files when the protons on their disk drives decay.4
To give you an idea of how Friends can be used, consider this slide from a talk I gave on an experiment I work on:

Figure 73: A real-world example of how Friends are used in an analysis chain.
In this diagram, “program A” (real name = gramsg4) creates a file
gramsg4.root with n-tuple gramsg4; “program B” creates a
file gramsdetsim.root; etc. Once the analysis chain is
complete, subsequent end-stage analysis programs (the kind of programs
you might be asked to write in a summer project) can use Friends to
view all these outputs as a single TTree.
This diagram is more complex than you might guess from comparing it to Figure 71. In the earlier figure, each column was just a number. Here each column contains a complicated data structure: a map of structs in C++, or a dict of lists in Python.
If you’ve gotten this far, you may ask: Can you combine both Chains and Friends? Yes, you can:
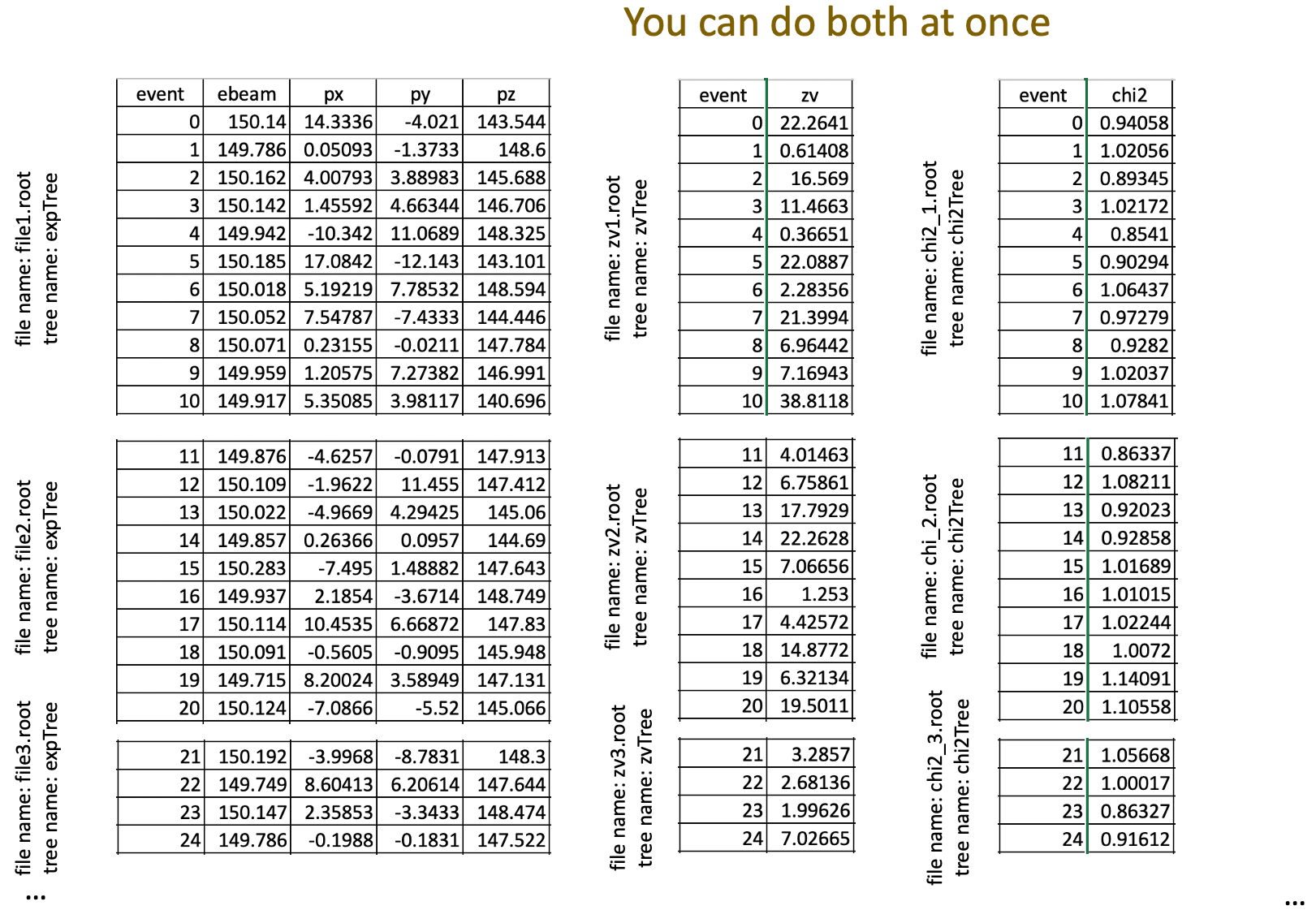
Figure 74: You can use both Chains and Friends in the same program.
Just as in real life, the chains of friendship can be the most important of all.
- 1
Here I mean “friend” in the sense of something we’ve gotten to know well, not in the sense of a ROOT Friend.
- 2
Whether Chris has spent a lifetime learning about topic C, or the C programming language, is not relevant to this discussion.
- 3
Whether this refers to a physics model that I’ve labeled “B”, or improving our understanding of the physics of the B meson, is not relevant to this discussion.
- 4
If you don’t get the joke: If protons decay, their lifetime is at least \(10^{34}\) years. That’s many multiples of the lifetime of the universe.